## 内容主体大纲1. **引言** - 数字货币的概念 - 数字货币与传统货币的区别 - 商务部对数字货币的政策支持2. **数字货...
在数字世界中,数据的获取与利用是推动信息技术发展的核心要素之一。随着网络技术的迅猛发展,Web3的到来为数据采集领域提供了新的机遇与挑战。本文将深入探讨Web3爬虫的概念、原理、应用场景及未来发展趋势。
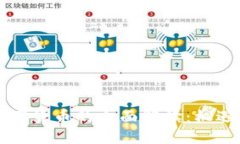
#### Web3与传统网络的区别Web3是一个分布式网络,让用户在享有自主权和隐私保护的同时,参与到网络的治理中来。相比传统的Web2,Web3更加强调去中心化、数据可控性与智能合约的应用。爬虫在Web3中的应用,不仅是在表面上抓取数据,而是深入到区块链的底层,获取各种世代的信息,使得数据的获取变得更为透明和安全。
#### Web3爬虫的原理Web3爬虫的核心在于通过区块链网络来采集数据。其工作机制包括通过智能合约与去中心化的存储系统进行交互,获取链上数据的同时,遵循链上数据的隐私和所有权规则。这一过程与传统爬虫通过HTTP请求获取数据的方式有所不同,因此Web3爬虫需要更复杂的技术支持。
#### Web3爬虫的应用场景Web3爬虫的应用场景广泛,包括数据市场、去中心化金融(DeFi)和NFT等领域。通过爬虫技术,可以对这些场景中的数据进行全面的分析与挖掘,从而获取对项目投资、市场趋势的深刻见解。
#### Web3爬虫的挑战虽然Web3爬虫有着巨大的潜力,但也面临诸多挑战。其中包括数据隐私问题、合法性与伦理问题以及技术难题等,需要开发者不断探索解决方案,以确保数据的合法获取与应用。
#### Web3爬虫的未来展望伴随着区块链技术的不断发展,Web3爬虫的前景也越来越明朗。未来,我们可以预计到Web3爬虫将会融入更多的智能算法、数据分析技术,以适应不断变化的市场需求,并可能催生出一系列新的商业模式。
### 常见问题解答 #### Web3爬虫与传统爬虫的最大不同是什么?Web3爬虫与传统爬虫的最大区别在于数据获取的来源与方式。传统爬虫依赖于HTTP协议,通过发送请求来抓取网页上的信息,通常聚焦于HTML文档的解析。在Web3中,数据不再仅仅存储在网页上,而是分布在区块链上,爬虫需要能够与智能合约交互,通过调用链上的API来获取链上数据。
此外,传统爬虫通常只处理公开网页的数据,而Web3爬虫需要处理更加复杂的去中心化数据结构,包括链上的状态、交易以及合约调用等。这要求Web3爬虫具备较强的技术能力,包括对区块链协议的理解和相关编程技能。
#### 如何保证Web3爬虫的数据合法性?
要确保Web3爬虫的数据合法性,首先要了解区块链网络的基本规则和法律框架。合法性通常涉及到用户的隐私权、数据使用的合规性等多个方面。例如,开发者需要规范自己爬虫的信息获取行为,避免侵犯用户的隐私或知识产权。
其次,使用合适的API接口也是确保合法性的关键方法。大多数区块链项目会提供官方API,开发者需遵循这些API使用的规定。此外,智能合约的设计中也应包含合法性审查机制,以确保每次数据的调用都在合理范围之内。
#### 对于初学者,如何入门Web3爬虫?对于初学者而言,入门Web3爬虫可以从几方面着手:
1. **学习基础知识**:首先,需要了解Web3的基本概念,熟悉区块链的工作机制,以及去中心化应用(DApp)的构成。这些知识为后续的爬虫开发打下基础。
2. **掌握必要的编程语言**:建议学习Solidity(智能合约开发语言)以及Python或JavaScript(爬虫开发语言),这些都是Web3爬虫开发的必备技能。
3. **实践开发**:可以通过参与开源项目、在线教程和社区讨论来提升实践技能。创建简单的Web3爬虫项目,从抓取基本的链上信息开始,逐步增加复杂的功能。
4. **关注安全和合规性**:在学习过程中,不断关注数据隐私与合规性的问题,确保在开发爬虫时尊重用户隐私与知识产权。
#### Web3爬虫在DeFi领域的作用是什么?
在去中心化金融(DeFi)领域,Web3爬虫能够扮演多个重要角色,其作用主要体现在:
1. **数据监控**:DeFi项目的数据极为动态,市场变化快,Web3爬虫可以实时监控链上的交易和合约状态,收集用户行为数据,帮助用户和开发者及时调整策略。
2. **市场分析**:通过对不同DeFi项目和代币的数据采集,爬虫能够为用户提供市场趋势分析、流动性状况等重要信息,为投资决策提供参考。
3. **风险评估**:风险是DeFi中不可忽视的因素,爬虫可以帮助分析合约的安全性及历史涨跌情况,从而评估潜在风险,为用户提供必要的风险提示。
4. **提高竞争力**:在信息迅速变化的环境中,拥有及时和可靠的数据优势可以帮助项目在竞争中脱颖而出,Web3爬虫正是其中的重要工具。
#### 使用Web3爬虫时应该注意哪些伦理问题?在使用Web3爬虫时,伦理问题是一个不容忽视的方面,主要包括:
1. **用户隐私**:确保爬虫收集的数据不会侵犯用户的隐私,尤其是涉及到链上交易信息时,必须遵循相关法律法规,防止用户信息泄露。
2. **数据的所属权**:区块链数据往往涉及到创作者权益,必须尊重数据的所有权,确保在获取和使用这些数据时已获得授权。
3. **信息透明**:当收集和使用数据后,爬虫开发者应保证数据使用的透明性,让用户了解其数据是如何被使用的,增加用户对项目的信任。
4. **避免恶意行为**:爬虫不应被用于恶意行为,例如竞争对手的数据攻击、价格操控等,这不仅可能导致法律责任也会损害项目的声誉。
#### 未来Web3爬虫将面临怎样的技术挑战?尽管Web3爬虫的前景光明,但在技术层面上依然面临诸多挑战,如下:
1. **数据获取效率**:Web3爬虫需要实现高效的数据抓取,而区块链的事务特性以及去中心化的存储机制可能会造成获取数据的速度变慢,开发者需要寻找的方法。
2. **处理复杂性**:区块链的智能合约设计复杂,爬虫需要解析合约的运行状态、历史交易、事件等多方面信息,增加了开发难度。
3. **更新与维护**:Web3的发展非常迅速,技术和协议的不断更新会导致爬虫需要定期维护与更新,以保证数据抓取的准确性。
4. **安全性问题**:面对网络攻击和数据泄露的风险,爬虫的安全性设计至关重要,需要注重数据传输的加密和存储策略。
5. **合规与监管**:随着Web3的发展,各种国家和地区可能出台不同的法律法规,爬虫开发者需要及时调整策略以符合新的合规要求。
6. **用户信任问题**:如何建立用户对爬虫捕获数据的信任也是一个长期的挑战,特别是在数据敏感性不断上升的当下,提供透明、安全的使用方式至关重要。
### 结论综上所述,Web3爬虫是一个充满潜力的领域,随着技术的进步和区块链的普及,其应用范围将不断扩大。然而,要有效利用这一新兴技术,开发者需要解决一系列技术、伦理与合规的问题,才能在快速发展的Web3时代中占据一席之地。


## 内容主体大纲1. **引言** - 数字货币的概念 - 数字货币与传统货币的区别 - 商务部对数字货币的政策支持2. **数字货...
### 内容主体大纲1. **引言** - Web3的基本概念与重要性 - 为什么Web3是下一代互联网的关键2. **Web3的发展历程** - 从Web1...
## 内容主体大纲1. **引言** - 数字货币的概念 - 数字货币的起源与发展2. **数字货币的种类** - 比特币 - 以太坊 - 稳定币...

### 内容主体大纲1. 引言 - 什么是Web3 - Web3与传统Web的区别 - 矿工在Web3中的位置2. Web3矿工的职责 - 维护网络安全 - 交易...